실 서비스의 아키텍처를 구조화할 때도 반드시 고려해야할 부분이고, 이 결정은 실제로 서비스에 큰 영향을 주게 된다.
가령 사용자가 갑자기 증가할 경우, 엄청난 수의 요청에 대한 처리를 어떻게 할 것인가는 Backend 에서 가장 중요하게 고려해야할 부분 중 하나이다.
Scaling 의 방법에는 크게 Scale Up 과 Scale Out 이 존재한다.
Scale Up: 서버 자체의 Spec 을 향상시킴으로써 성능을 향상시킨다. Vertical Scaling 이라 불리기도 한다. 서버 자체의 갱신이 빈번하여 정합성 유지가 어려운 경우(주로 OLTP 를 처리하는 RDB 서버의 경우) Scale Up 이 효과적이다.
성능 향상에 한계가 있으며 성능 증가에 따른 비용부담이 크다. 대신 관리 비용이나 운영 이슈가 Scale Out 에 비해 적어 난이도는 쉬운 편이다. 대신 서버 한대가 부담하는 양이 많이 때문에 다양한 이유(자연 재해를 포함한다...)로 서버에 문제가 생길 경우 큰 타격이 불가피하다.
Scale Out: 서버의 대수를 늘려 동시 처리 능력을 향상시킨다. Horizon Scaling 으로 불린다. 단순한 처리의 동시 수행에 있어 Load 처리가 버거운 경우 적합하다. API 서버나, 읽기 전용 Database, 정합성 관리가 어렵지않은 Database Engine 등에 적합하다.
특히 Sharding DB 를 Scale Out 하게 된다면 주의해야하는데, 기존의 샤딩 알고리즘과 충돌이 생길 수도 있고(샤드가 갯수에 영향을 받을 경우...) 원하는 대로 부하의 분산이 안생길 수 있으니 각별히 주의할 필요가 있다.
스케일 아웃은 일반적으로 저렴한 서버 여러 대를 사용하므로 가격에 비해 뛰어난 확장성 덕분에 효율이 좋지만 대수가 늘어날 수록 관리가 힘들어지는 부분이 있고, 아키텍처의 설계 단계에서부터 고려되어야 할 필요가 있다.
요즘은 클라우드를 사용하기 때문에 Scaling 에 있어서 큰 이점이 있으며, 서비스의 목표치에 알맞게 Scalability 를 설계하고 두 스케일링 방법을 모두 적용시키는 것이 일반적이다.
JVM 은 Java 코드 및 Application을 동작시킬 수 있도록 런타임 환경을 제공해주는 Java Engine 이다.
JVM 은 JRE의 일부분이며 Java 개발자로서 JVM 의 동작을 이해하는 것은 Java 구동 환경과 JRE(Java Runtime Environment) 을 이해하는 데 있어서 아주 중요한 부분이다.
Java 가 추구하는 가치는 WORA(Write Once Run Anywhere) 이며, 이는 모든 자바의 코드는 JVM 이라는 환경 위에서 동작하면서 어느곳이든 이식이 가능하다는 뜻을 포함하고 있다.
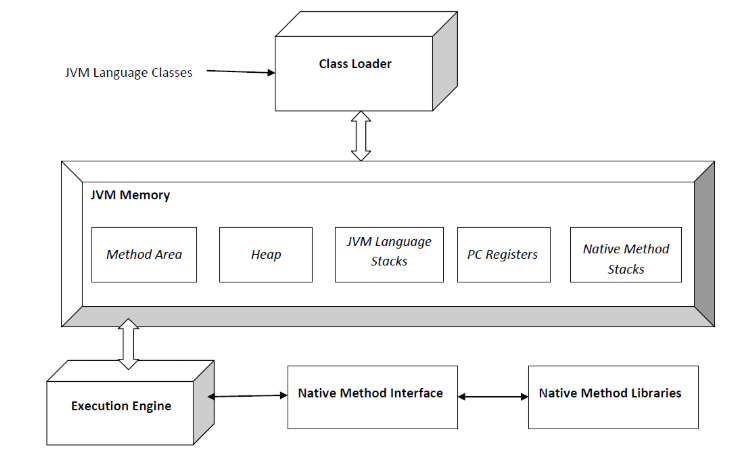
먼저 JVM 의 아키텍처는 다음과 같다.
하나하나 동작을 살펴보도록 하자.
Java Application 의 동작은 다음과 같은 순서로 이루어진다.
(1) Java JIT Compiler 가 Java 코드를 해석한다. Java Compiler 는 해석한 .java 코드를 .class 파일 형태로 해석결과로 만든다.
(2) 클래스 로더에 의해 .class 파일들은 다음 단계들을 거치며 해석된다.
- Loading : 클래스 파일에서 클래스 이름, 상속관계, 클래스의 타입(class, interface, enum) 정보, 메소드 & 생성자 & 멤버변수 정보, 상수 등에 대한 정보를 로딩해서 Binary 데이터로 변경한다.
- Linking : Verification 과 Preparation, Resolution 단계를 거치면서 바이트코드를 검증하고 필요한 만큼의 메모리를 할당한다. Resolution 과정에서는 Symbolic Reference 를 Direct Reference 등으로 바꿔준다.
- Initialization : static block 의 초기화 및 static 데이터들을 할당한다. Top->Bottom 방식으로 클래스들을 해석한다.
Context Switching 은 면접에서 지원자의 기본기를 검사할 목적으로 단골로 등장하는 질문이자, CS의 중요한 기본 지식이기도 하다.
Context Switching 이란 CPU가 한 개의 Task(Process / Thread) 를 실행하고 있는 상태에서 Interrupt 요청에 의해 다른 Task 로 실행이 전환되는 과정에서 기존의 Task 상태 및 Register 값들에 대한 정보 (Context)를 저장하고 새로운 Task 의 Context 정보로 교체하는 작업을 말한다.
여기서 Context란, CPU 가 다루는 Task(Procee / Thread) 에 대한 정보로 대부분의 정보는 Register 에 저장되며 PCB(Process Control Block) 으로 관리된다.
여기서 Process 와 Thread 를 처리하는 ContextSwitching 은 조금 다른데, PCB는 OS에 의해 스케줄링되는 Process Control Block이고, Thread 의 경우 Process 내의 TCB(Task Control Block) 라는 내부 구조를 통해 관리된다.
Task 의 PCB 정보는 Process Stack, Ready Queue 라는 자료구조로 관리가 되며, Context Switching 시 PCB 의 정보를 바탕으로 이전에 수행하던 작업 혹은 신규 작업의 수행이 가능하게 된다.
PCB는 주로 다음과 같은 정보들을 저장하게 된다.
(1) Process State : 프로세스 상태
(2) Program Counter : 다음에 실행할 명령어 Address
(3) Register : 프로세스 레지스터 정보
(4) Process number : 프로세스 번호
Context Switching 시, Context Switching 을 수행하는 CPU 는 Cache 를 초기화하고 Memory Mapping 을 초기화하는 작업을 거치는 등 아무 작업도 하지 못하므로 잦은 Context Switching 은 성능 저하를 가져온다.
일반적으로 멀티 프로세스를 통해 PCB를 Context Switching 하는 것보다 멀티 쓰레드를 통해 TCB 를 Context Switching 하는 비용이 더 적다고 알려져있다.
주로 Context Switching 은 Interrupt 에 의해 발생되는데, Hardware 를 통한 I/O 요청이나, OS / Driver 레벨의 Timer 기반 Scheduling 에 의해 발생한다.
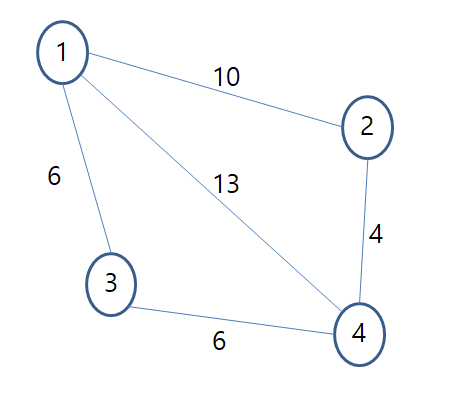
import java.util.PriorityQueue;
import java.util.Scanner;
public class Main {
private static int INF = 1000000000;
private static class Node implements Comparable<Node> {
int idx;
int val;
int getIdx() {
return idx;
}
int getVal() {
return val;
}
Node(int idx, int val) {
this.idx = idx;
this.val = val;
}
@Override
public int compareTo(Node o) {
return this.getVal() - o.getVal();
}
}
private static int djikstra(int[][] dist, int n, int src, int dest) {
PriorityQueue<Node> priorityQueue = new PriorityQueue<>();
for (int i = 1; i <= n; i++) {
if (src != i && dist[src][i] < INF) {
priorityQueue.offer(new Node(i, dist[src][i]));
}
}
while (!priorityQueue.isEmpty()) {
Node next = priorityQueue.poll();
int nidx = next.getIdx();
int ndist = next.getVal();
for (int i = 1; i <= n; i++) {
if (dist[nidx][i] != INF && ndist + dist[nidx][i] < dist[src][i]) {
dist[src][i] = ndist + dist[nidx][i];
priorityQueue.offer(new Node(i, dist[src][i]));
}
}
}
return dist[src][dest];
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
int m = scanner.nextInt();
int[][] dist = new int[1001][1001];
for (int i = 0; i < 1001; i++) {
for (int j = 0; j < 1001; j++) {
dist[i][j] = INF;
}
}
for (int i = 0; i < m; i++) {
int a = scanner.nextInt();
int b = scanner.nextInt();
int d = scanner.nextInt();
dist[a][b] = Math.min(dist[a][b], d);
}
int src = scanner.nextInt();
int dest = scanner.nextInt();
System.out.println(djikstra(dist, n, src, dest));
}
}
그렇다면 성능 테스트를 어떻게 할 것이고 어떻게 병목현상을 해결하여 개선을 이루어낼 것인가가 관건이며, 이를 위해서는 단순히 코드를 효율적으로 짜는 것 이상의 학습이 필요하다.
"성능" 에 대한 이해와 "테스트" 에 대한 이해, Performance Engineering 에 대한 이해가 모두 필요한 것이다.
그렇다면 먼저 서버의 성능 측정에 앞서 알아두어야할 용어들을 정리해보자.
(1) Response Time : 클라이언트의 요청을 서버에서 처리하여 응답해주는데까지 걸리는 전체 시간을 말한다.
실제 요청이 들어간 시점부터 네트워크를 거치고 비즈니스 로직의 처리가 끝난 후 다시 클라이언트가 응답을 받는 시점까지 걸리는 시간을 말한다.
(2) Think Time : 사용자가 다음 Request 를 보내기 전까지 활동하는 시간을 말한다. 실제 별도의 서버 요청을 하지않고 웹문서를 보거나 컨텐츠를 즐기는 시간을 Think time 으로 분류한다.
첫번째 요청에서 다음 요청을 보낼때까지의 시간이므로 Request Interval 로 부르기도 한다.
(3) Concurrent Users : 말그대로 동시에 서비스를 사용하는 유저를 말한다. 웹서버 / 세션서버 등 서버의 종류에 따라 유저의 행동양식에 대한 분류는 매우 다양해지게 된다.
일반적으로 Concurrent User 는 Active User 와 Inactive User 로 분류한다.
- Active User : 실제 Request 를 보내고 Response 를 대기 혹은 Connection 을 잡고 있는 유저를 말한다.
일반적으로는 Request 에 대해 실제 Transaction 을 발생시키는 유저에 대해 언급한다.
여기서 포함되는 유저들의 목록에는 실제로 서버에서 클라이언트의 요청을 받을 시, Connection Pool 을 모두 가져가는 유저들과, Connection Pool 의 할당을 대기하고 있는 Pending User 들 역시 Active User 에 포함된다는 점이다.
- Inactive User : 실제 Request 를 수행하지 않고 대기중인 유저를 말한다. 서버의 종류에 따라 연결을 유지하고 있는 유저의 경우에도 Inactive User 로 보기도 한다.
웹서버의 경우 대부분의 Inactive User 는 Think time 을 갖는 유저로 간주된다.
(4) Throughput : 서버가 클라이언트에 송신한 데이터량
(5) Vuser : Virtual User - 주로 퍼포먼스 테스트를 위해 만드는 가상 유저
(6) MRT : Mean Response Time 의 약자로 유저들에 대한 평균 응답시간을 말한다.
(7) TPS : Transaction Per Second 의 약자로 주로 서버 성능의 척도가 된다. 초당 트랜잭션 처리 수를 의미한다.
일반적으로 TPS = AU / MRT 라는 공식에 따라 Active User 의 수에 비례하고 유저들에 대한 평균 응답시간(MRTT)에 반비례한다.
(8) Scenario : 테스트를 위한 시나리오를 말한다. 정확한 TPS 측정을 위해서 가장 중요한 부분 중 하나로, 실제 서비스에서 유저가 어느정도 비율로 어떤 API 를 호출할지 예측하는 과정이 필수적이다.
Service Architecture 를 잘 이해하고 있어야됨은 물론이고, 이에 따라 API 호출의 비율과 그에 맞는 튜닝으로 서비스의 질을 향상시켜야 한다.
위의 용어를 이해했으면 다음으로 퍼포먼스 테스트를 위한 프로세스를 정리해보자.
1. 먼저 서비스의 목표와 그를 위한 규모를 측정해야 한다.
2. 서비스 내에서 사용자의 요청 빈도 수를 예측하고, 그에 알맞게 테스트 시나리오를 만든다.
3. 테스트 시나리오에 맞게 다양한 방향으로 테스트를 진행한다.
여기서 테스트는 Stress Test / Performance Test / Load Test 가 복합적으로 진행되어야 한다. 각 테스트별 한계값 임계치를 측정하는 것이 중요하며, 각각의 테스트 결과는 서로에 영향을 미치게 될 것이다.
4. Stress Test / Load Test / Performance Test 를 통해 현재 시스템의 부하 한계치, 퍼포먼스 등이 측정이 되었다면, 모듈별로 분석해서 튜닝하는 작업이 필요하다.
비즈니스 로직 뿐 아니라 Database / Network / Middleware / Infrastructure 등을 모두 튜닝하는 것이 중요하다.
5. 튜닝을 통해 테스트를 다시 수행하며 서비스의 한계치를 다시 측정한다. 목표에 이를 때까지 4~5 과정을 반복한다.
위의 테스트 Process 를 거치면 실제 생각했던것과 다른 상황을 많이 마주치게 된다.
가령, 우리는 응답시간이 큰 변동폭이 없을 것이며, 가용 자원량 만큼 TPS 가 올라갈 것이라 예측하고 한계점을 측정하겠지만, 실제로는 가용자원의 양은 처음에 급격이 증가하되, 어느정도 TPS 이상이 확보되면 일정해지며 응답시간은 TPS 증가에 따라 기하급수적으로 올라가게 된다.
이는 주로, Service architecture 가 Caching 을 하기 때문에 가용자원에 대한 부분을 상당 부분 부담해주기 때문이며, 응답시간의 경우 부하가 쌓이는 만큼 Connection Pool 에서 유저의 요청에 대한 Pending 이 생기기 때문이다.
아직 Performance Engineering 에 대해서는 지식이 짧아 정리하지 못했는데, 계속해서 공부를 해보면서 추가 포스팅 하도록 해야겠다.
실제 라이브 서비스를 위해 서버 산정을 할 때, 서비스 규모에 걸맞는 트래픽을 감당하기 위한 테스팅은 필수적이다.
근래에는 클라우드의 발전으로 Scalability 나 Elasticity 를 확보할 수 있는 많은 방법과 기술들이 생겼다고는 해도, 결국 해당 솔루션을 사용하는 것은 "비용" 이며 서버개발자라면 이 비용을 최소화하고 효율적인 서버를 구축해내는 것이 "실력" 을 증명해내는 일이다.
여기서 피할 수 없는 백엔드 테스트의 종류들이 나타나는데, 일반적으로 스트레스 테스트 또는 부하 테스트라고 알려진 테스트들이다.
이 테스트들은 중요하지만, 개발자들이라도 차이를 잘 모르는 사람들이 꽤나 있고 서비스의 규모가 작다면 혼용되어 쓰는 경우가 다수이기 때문에 정리해서 알아둘 필요가 있다.
(1) Load Testing (부하 테스트)
말그대로 시스템이 얼마만큼의 부하를 견뎌낼 수 있는 가에 대한 테스트를 말한다.
보통 Ramp up 이라하여 낮은 수준의 부하부터 높은 수준의 부하까지 예상 트래픽을 꾸준히 증가시키며 진행하는 테스트로, 한계점의 측정이 관건이며, 그 임계치를 높이는 것이 목적이라 할 수 있다.
일반적으로 "동시접속자수" 와 그정도의 부하에 대한 Response Time 으로 테스트를 측정한다.
예를들어 1분동안 10만명의 동시접속을 처리할 수 있는 시스템을 만들수 있는지 여부가 테스트의 주요 관건이 된다.
(2) Stress Testing (스트레스 테스트)
스트레스 테스트는 "스트레스받는 상황에서 시스템의 안정성" 을 체크한다.
가령 최대 부하치에 해당하는 만큼의 많은 동시접속자수가 포함된 상황에서 시스템이 얼마나 안정적으로 돌아가느냐가 주요 관건이 된다.
스트레스 상황에서도 시스템의 모니터링 및 로깅, 보안상의 이슈나 데이터의 결함 등으로 서비스에 영향이 가서는 안되므로 결함에 대한 테스트가 일부 포함된다.
가령 메모리 및 자원의 누수나 발생하는 경우에 대한 Soak Test 나 일부러 대역폭 이상의 부하를 발생시키는 Fatigue Test 가 포함된다.
이처럼 부하가 심한 상황 또는 시스템의 복구가 어려운 상황에서 얼마나 크래시를 견디며 서비스가 운영될 수 있으며 빠르게 복구되는지, 극한 상황에서도 Response Time 등이 안정적으로 나올 수 있는지 등을 검사하게 된다.
예를들어 10만명의 동시접속 상황에서 크래시율을 얼마나 낮출 수 있는가, 혹은 데이터 누락을 얼마나 방지할 수 있는가 에 대한 테스팅이 있을 수 있다.
(3) Performance Testing (퍼포먼스 테스트)
Load Test 와 Stress Test 의 모집합 격인 테스트의 종류이다. 리소스 사용량, 가용량, 부하 한도(Load Limit) 를 포함해서 응답시간, 에러율 등 모든 부분이 관건이 된다.
특정 상황에서 어떤 퍼포먼스를 보이는지에 대한 측정이 주가 되며, 서비스의 안정성보다는 퍼포먼스 자체에 집중한다.
주로 서비스적 관점에서는 Performance Test 보다는 Load Test 나 Stress Test 가 더 중점이 되며, 시스템 전체적인 성능의 양적 측정과 같은 관점에서 Performance Test 로 분류한다.
보통 그럴 때에 수행하는 테스트로 Benchmark 라고 하기도 한다.
위와 같은 종류의 테스트 들을 수행하는 데 있어 제일 중요한 부분 중 하나는 모니터링과 리포팅이라고 할 수 있겠다.
SOA(Software Oriented Architecture) 란, 2000년대 초반부터 IT 업계 전반에 걸쳐 녹아든 IT System 의 패러다임이다.
고전의 Client-Server Architecture 에서 EJB 로 대표되는 n-Tier Model Architecture 로 진화한 웹 아키텍쳐는 2000년대 이후부터 비즈니스 요구사항에 발빠르게 대처하기 위한 구조로 Service-Oriented Architecture 라는 아키텍쳐로 진화한다.
SOA 란, 그전까지의 Application 의 Massive 한 기능들을 비즈니스적인 용도로 분류하고 기능 단위로 묶어서 하나의 표준 Interface 를 통해 각각을 "서비스" 로써 조합하는 Software Architecture 이다.
IT 업계의 요구사항이 많아지고 변화가 빨라짐에 따라 이에 대처하기 위해 나타난 Architecture 이고, 구성요소를 3가지로 분류한다.
1. Service Consumer - 서비스의 사용자. 사용자는 실제 클라이언트(End-User) 또는 다른 서비스가 될 수 있다.
2. Service Provider - 서비스 사용자에 요청에 맞는 서비스를 제공. Provider 는 다른 Service 의 Consumer 가 될 수도 있다.
3. Service Registry - 서비스의 정보를 저장한다. Provider 가 Registry 를 통해 Consumer 에게 서비스를 제공한다.
여기서 중요한건 Service Provider 와 Service Consumer 로, 이들은 실제 서비스의 유저 뿐 아니라 소프트웨어 아키텍처 내부의 "모듈" 도 대상이 될 수 있다.
즉, SOA 는 비즈니스적으로 구분된 Service 들을 느슨하게 연결하며, 각 컴포넌트를 독립적으로 운용하여 조립이 가능하게끔 한다.
일반적으로 Service 를 위해 서비스 기능별로 모듈을 분리하고, 각 모듈이 다른 모듈과 상호작용할 수 있도록 만들어진 Architecture 를 SOA 라고 이해하면 된다.
여기까지 이해했으면 떠오르는 최근의 Architecture 모델이 있을 수 있다.
바로 Micro Service Architecture(MSA) 이다.
Micro Service Architecture 역시 각 서비스를 독립적으로 운용하며 서비스들을 조합하여 End User 에게 서비스를 제공하는 형태로 이루어진다. 그렇다면 이는 SOA 와 같은 아키텍처인가?
결론부터 말하자면, Micro Service Architecture 는 SOA 의 부분집합이라고 할 수 있다.
정확히는 SOA 는 패러다임이며, 그를 위한 Architecture 의 초안이고, Micro Service Architecture 는 SOA 의 패러다임을 따르되, 그 아키텍처를 따르지 않는다.
SOA 와 MSA 의 차이점
1. SOA 는 모듈의 의존성은 줄이되 모듈 내에서 공유할 수 있는건 최대한 공유하는 정책을 사용한다.
반면, MSA 는 가능한 공유하지 않고 모듈들이 독립적으로 운용될 수 있도록 아키텍처를 디자인 한다.
2. SOA 는 서비스의 Flow 를 유지하려하지만, MSA 는 Flow 의 구별을 요구한다.
가령, 서비스 내에서 결제를 하고자 할때, SOA 는 관련된 루틴을 수행하여 결제를 지원함으로써, 유저에게 제공해주는 "서비스" 를 1차 목적으로 한다.
반면, MSA 는 유저에게 관련된 루틴과 결제 루틴을 별도로 이용하게끔 한다. 즉 서비스 내의 독립이 아닌 독립된 서비스를 지향한다.
그렇다보니 SOA 아키텍처는 대게 어느정도 업격한 Protocol 과 Message 체계를 운용하게 되고, MSA 의 경우 별도의 체계가 없이 경량화된 프로토콜을 통해 운용되게 된다.
3. SOA 는 서비스들의 재사용에 중점을 두지만 MSA 는 서비스들의 독립을 추구한다.
이는 블로그 내 다른 포스팅에서 언급한 적 있는 Monolithic Architecture 와 유사한 부분으로, SOA 는 MSA 에 비해 보다 Monolithic Architecture 에 가깝다.