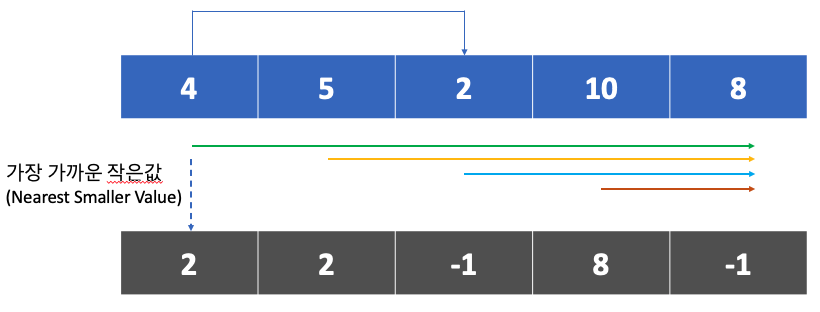
보통 트리의 순회를 구현하게되면, 간단한 재귀함수의 호출 형태로 구현하게 되는데, 이 때 고려해야할 점은 재귀함수의 호출은 Stack 메모리의 희생을 요구한다는 점이다.
즉, 순회만으로도 노드의 갯수가 많아진다면 Stack Overflow 에러가 발생하게 된다.
의외로 Tree 의 Traversal 을 Recursion 이 아닌 Iteratation 로 구현하는데 어려움을 겪을 수 있어 정리해보았다.
public class Algorithm {
/***
TreeMap 은 index 를 키값으로하는 Map 의 형식으로 저장된 n-Ary tree
TreeValues 는 index 에 따라 트리의 Value 를 저장한 리스트
**/
public void postOrderTraversal(Map<Integer, List<Integer>> treeMap, List<Integer> treeValues) {
Stack<Integer> returnStack = new Stack<>(); //순회할 노드들의 인덱스를 저장하는 스택
Stack<Integer> resultStack = new Stack<>(); //순회하고 나온 Return 값을 저장하는 스택
returnStack.push(0); //0번 노드를 루트로 가정하고 루트부터 순회
while (!returnStack.isEmpty()) {
int next = returnStack.pop();
resultStack.push(treeValues.get(next));
if(treeMap.containsKey(next)) {
List<Integer> children = treeMap.get(next);
for(int child : children) {
returnStack.push(child);
}
}
}
while (!resultStack.isEmpty()) {
System.out.println(resultStack.pop()); //후위 순서대로 출력
}
}
}
귀찮아서 별도의 노드 클래스 없이 Map 과 List 를 활용해 트리 구조를 제공하였으나 ;;
import java.util.PriorityQueue;
import java.util.Scanner;
public class Main {
private static int INF = 1000000000;
private static class Node implements Comparable<Node> {
int idx;
int val;
int getIdx() {
return idx;
}
int getVal() {
return val;
}
Node(int idx, int val) {
this.idx = idx;
this.val = val;
}
@Override
public int compareTo(Node o) {
return this.getVal() - o.getVal();
}
}
private static int djikstra(int[][] dist, int n, int src, int dest) {
PriorityQueue<Node> priorityQueue = new PriorityQueue<>();
for (int i = 1; i <= n; i++) {
if (src != i && dist[src][i] < INF) {
priorityQueue.offer(new Node(i, dist[src][i]));
}
}
while (!priorityQueue.isEmpty()) {
Node next = priorityQueue.poll();
int nidx = next.getIdx();
int ndist = next.getVal();
for (int i = 1; i <= n; i++) {
if (dist[nidx][i] != INF && ndist + dist[nidx][i] < dist[src][i]) {
dist[src][i] = ndist + dist[nidx][i];
priorityQueue.offer(new Node(i, dist[src][i]));
}
}
}
return dist[src][dest];
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
int m = scanner.nextInt();
int[][] dist = new int[1001][1001];
for (int i = 0; i < 1001; i++) {
for (int j = 0; j < 1001; j++) {
dist[i][j] = INF;
}
}
for (int i = 0; i < m; i++) {
int a = scanner.nextInt();
int b = scanner.nextInt();
int d = scanner.nextInt();
dist[a][b] = Math.min(dist[a][b], d);
}
int src = scanner.nextInt();
int dest = scanner.nextInt();
System.out.println(djikstra(dist, n, src, dest));
}
}