RPC 는 기술 문서를 읽다보면, 현업에서 흔히 접하게 되는 용어지만 은근히 개념을 이해하기는 쉽지 않다.
RPC 의 개념을 인터넷에서 (혹은 최근에 핫한 ChatGPT 에서) 찾아보자면 다음과 같이 나온다.
Remote Procedure Call 은 원격 컴퓨터나 프로세스에 존재하는 함수를 호출하는데 사용하는 프로토콜로, 원격지의 프로세스를 동일 프로세스의 함수를 호출하는 것 처럼 사용하는 것을 말한다.
하지만 위의 개념을 읽고 한번에 와닿는 사람들은 많지 않을 것이라고 생각한다. 실제로 현업의 엔지니어들도 애매모호하게 해석하게 되는 개념 중 하나이다.
그도 그런게 RPC 는 특정 프로토콜 이라기 보다는 전통적인 개념의 API 호출 규약이기 때문이다.
예시를 보면 이해가 보다 쉬울 것이다.
POST /sayHello HTTP/1.1
HOST: api.example.com
Content-Type: application/json
{"name": "Tom"}
위의 예시는 HTTP 위에서 구현된 RPC 방식의 예시이다. 위의 HTTP 스키마는 HTTP Client (웹 브라우저) 를 통해 HTTP Server (웹 서버) 에 전달될 것이고, WAS 는 위의 프로토콜을 처리하기 위한 로직을 구현하게 된다.
여기서 보통은 "그냥 HTTP 프로토콜 아닌가?" 라는 생각이 들 것이고, 그 생각은 맞다.
하지만 일반적인 REST API 처럼 보인다면, 엄밀히 따지자면 그렇지 않다. RPC 와 REST 의 차이점은 다음과 같다.
| REST | RPC | |
| Protocol | HTTP | 프로토콜에 무관 (TCP, UDP, HTTP, WebSocket, ...) |
| Scheme | Resource 기반의 API 인터페이스 (예) 강아지 목록을 반환하는 API 를 GET /dogs 로 설계 |
Action 기반의 API 인터페이스 (예) 강아지 목록을 반환하는 API 를 POST /listDogs 로 설계 |
| Design | RESTful API 는 Stateless 를 전제 | 제약이나 규약이 없음 |
즉, RPC 는 서버와 클라이언트가 통신하기 위한 API 의 통신 패러타임 중 하나이고, REST API 와 비교될 수 있는 차원의 개념이라고 할 수 있다.
RPC 는 기본적으로 정해진 구조를 갖고있지는 않지만, 기본적인 Terminology 를 몇가지 갖고있다.
- IDL (Interface Definition Language) : 서로 다른 언어로 작성된 서비스들 사이에서 공통된 인터페이스를 정의하기 위한 중간 언어
- Stub : 서버와 클라이언트는 서로 다른 주소 공간을 사용하므로 함수 호출에 사용된 매개변수를 변화해줘야하며, 그 역할을 담당한다
- client stub - 함수 호출에 사용된 파라미터의 변환(Marshalling) 및 함수 실행 후 서버에서 전달된 결과의 반환
- server stub - 클라이언트가 전달한 매개변수의 역변환(Unmarshalling) 및 함수 실행 결과 변환을 담당
그리고 위의 개념에 따라서 다음과 같은 순서로 통신이 이뤄지게 된다.
- IDL 을 사용하여 호출 규약을 정의한다. IDL 파일을 rpcgen 으로 컴파일하면 stub code 가 자동으로 생성
- Stub Code 에 명시된 함수는 원시 코드의 형태로 상세 기능은 server 에서 구현된다. Stub 코드는 서버/클라이언트에서 각각 빌드된다
- 클라이언트에서 stub 에 정의된 함수를 사용 시 client stub 은 RPC runtime 을 통해 함수를 호출하고 서버는 수신된 Procedure 호출에 대해 처리 후 결과를 반환
- 클라이언트는 서버로부터 응답을 받고 함수를 로컬에 있는 것처럼 사용할 수 있다
이해가 잘 되지 않는다면 쉽게 말해서, RPC 는 이를 해석하고 처리하기 위한 Client / Server 가 존재하며, 그 사이에 규약(IDL) 을 정의하고 IDL 을 클라이언트측 / 서버측 Stub 을 통해 해석하고 비즈니스 로직을 구현한다고 보면 된다.
RPC 는 RESTful API 에 비해 복잡하며, 프로젝트에 따라 Learning Curve 가 있기 때문에,
근래에 RPC 의 개념은 전통적인 방식으로는 잘 사용되지 않으며 gRPC (Google RPC) 와 같은 발전된 개념으로 사용되어진다.
RESTful API 가 갖는 개념적 제한에서 벗어나서 보다 자유로운 설계를 위해 사용되는 개념이고, gRPC 와 같은 Modern RPC 는 Micro Service Architecture 등에서 Internal Bidirectional Communication 을 위해 사용되어진다.
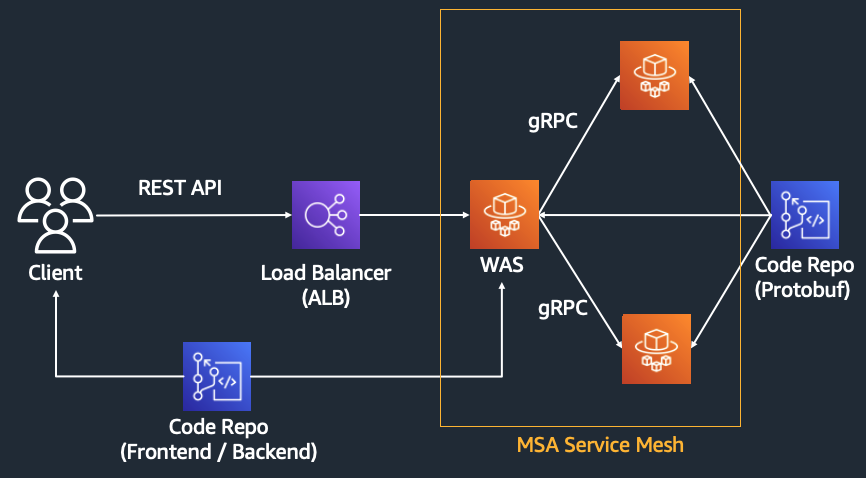
위의 예시는 gRPC 를 이용해서 Micro Service Architecture 를 구현하는 방식을 보여준다. gRPC 의 경우 Protobuf 를 스키마로 사용하기 때문에, 통신을 위한 서버-클라이언트 간에 .proto 파일에 대한 별도 관리가 필요하다.
Protobuf 는 구글이 만든 언어 및 플랫폼 중립적인 Data Format 으로, 일반적인 JSON Serialize / Deserialize 대비 효율적인 통신이 큰 장점이다. 관련해서는 블로그의 다음 글을 참고해볼 수 있다.
현업에서 RPC 는 주로, 웹 서비스 보다는 게임이나 IoT, Device 등 Non HTTP 기반 산업에서 보다 많이 보이는 형태이지만 Micro Service Architecture 가 시장에 자리잡기 시작하면서 Modern RPC 형태로 많이 보이고 있다.
기술이 어떻게 진화할지 모르겠지만 여러 기술적인 문제를 해결하기 위한 시도 중 하나로 알아둘 법한 패러다임이라고 생각되어진다.
'Server > Basic' 카테고리의 다른 글
| CSR 기반의 Modern Frontend 환경과 SPA 환경 구성 파이프라인 알아보기 (0) | 2022.05.18 |
|---|---|
| 동적 컨텐츠(Dynamic Contents)와 정적 컨텐츠(Static Contents) 그리고 캐싱 (0) | 2019.08.28 |
| Scaling 의 종류에 대한 정리 (0) | 2019.06.02 |
| 서버의 성능 테스트를 시작한다면 꼭 알아야 할 것들 (0) | 2019.05.18 |
| load testing 과 stress testing, performance testing 에 대한 비교 (0) | 2019.05.16 |