분산처리 환경을 구축하는 데 있어서 로드밸런서의 역할은 핵심적이다.
클라우드 환경에서 분산처리를 위한 아키텍처를 설계한다면, AWS 의 Load Balancer 를 이용해볼 수 있다.

Amazon Web Service 가 Provisioning 하는 Load Balancer 는 ELB(Elastic Load Banacing) 서비스라 하며, 기본적으로 Logging, Cloud Watch 를 통한 지표, 장애 복구, Health Check 와 같은 기능들을 제공한다.
ELB 서비스의 종류로는 2019년 8월 기준으로 3가지 종류가 있다.
(1) Classic Load Balancer
가장 기본적인 형태이자 초기에 프로비저닝되던 서비스로, 포스팅 등에 나오는 설명에 단순히 ELB 라고 나와있으면 Classic Load Balancer 를 말하는 경우가 많다.
L4 계층부터 L7 계층 까지 포괄적인 로드밸런싱이 가능하며, 따라서 TCP, SSL, HTTP, HTTPS 등 다양한 형태의 프로토콜을 수용할 수 있고 Sticky Session 등의 기능도 제공해준다.
특징적으로 Classic Load Balancer 는 Health Check 를 할 때, HTTP 의 경우 /index.html 경로를 참조한다.
즉, 웹서버 인스턴스의 경로에 /index.html 가 포함되어있지 않다면(404) Health Check 를 실패한다는 뜻이다...
따라서 이럴 때에는 Health Check 를 위한 프로토콜만 TCP 로 바꾸고 포트만 80 으로 체크하게 하는 방법이 있다.
중요한 특징으로... CLB 는 로드밸런서가 url 하나를 가질 수 있다. 즉, CLB 로 매핑되어있는 인스턴스들은 무조건 하나의 URL 을 통해 접근하게 된다.
(2) Application Load Balancer
Classic Load Balancer 이후 출시된 서비스로 HTTP 및 HTTPS 트래픽 로드밸런싱에 최적화되어있다.
L7 계층에서 작동하며 Micro Service Architecture 와 같은 Modern 환경을 겨냥한 많은 강점들이 있는데, WebSocket 이나 HTTP/1.1 이상의 프로토콜에 대한 지원, 향상된 라우팅 정책과 사용자의 인증 까지도 지원을 해준다.
웹서비스를 목적으로 한다면 기존 Classic Load Balancer 가 갖고 있던 장점 이상의 강점들을 많이 포함하고 있다.
단 L7 계층에서 작동하기 때문에 TCP 등에 대한 밸런싱은 지원되지 않는다.
직접 사용해서 구축 할때에 Classic Load Balancer 에 비해 좀 더 구축이 편하고 웹서버 밸런싱에 있어서는 확실히 다양한 옵션이 있다. Health Check 경로 또한 지정할 수 있으며, 기본이 / 로 정해져있다.
CLB와 다르게 ALB 는 host-based Routing 과 path-based Routing 을 지원한다. Content Based Routing 이라고도 하며 ALB 에 연결된 인스턴스들은 여러개의 URL 과 path 를 가질 수 있다.
(3) Network Load Balancer
Load Balancer 중 성능적으로 최적의 로드밸런싱을 지원한다. TCP, UDP 등의 서버를 구축할 때 해당 프로토콜 들에 대해 굉장히 낮은 지연 시간으로 최적의 성능을 보여준다고 한다.
사용해본적이 없는데... 사용해본다면 좀 더 포스팅 내용을 보강해야겠다.
로드밸런서에 EIP 를 직접 붙일 수는 없고, 필요하다면 DNS 의 도메인 네임 대신 CNAME 을 사용하거나 Route53 서비스와 같이 사용해야 한다. 그 이유는... ELB 역시 서버이기 때문에, 부하 상황에서 오동작의 위험이 있고 그에 따라 자체적으로 Scale In - Scale Out 을 수행하기 때문이다. (즉, IP 를 지정할 서버가 한대가 아니게 될 수 있다.)
또한, ELB 는 Multi-AZ 환경에서 "내부적으로는" 각 Availability Zone 별로 구성된다. 이 때 트래픽의 분배는 AZ 당 ELB 사정에 맞게 분배되므로... Multi AZ 환경에서는 각 Availability Zone 별 인스턴스의 숫자를 동일하게 맞춰주는 것이 좋다. (동일하게 맞추지 않으면 특정 Zone 의 인스턴스들에 트래픽이 몰릴 수 있다.)
로드밸런서를 통해 Cloud 환경에서 아키텍처를 설계할 때에는 Private Subnet 들에 EC2 인스턴스들을 배치해둔 상태에서, ELB로 트래픽을 연결할 수 있도록 인스턴스들을 연결시켜주고, Public 영역에 위치시켜 놓는 식으로 구성을 한다.
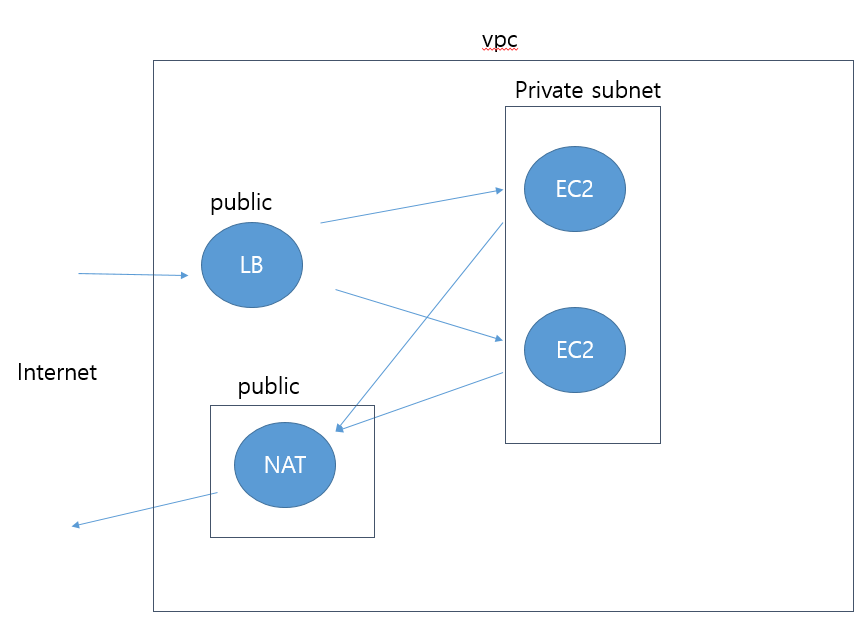
혹은, ELB 자체는 VPC 내부에 형성시켜 두고, ELB로 들어온 트래픽을 Private Subnet 으로 전개시켜주며, 인터넷에 연결을 위한 Public NAT 를 두고 출력을 해당 NAT 를 거치게 하는 방식도 있다.
'Cloud > AWS' 카테고리의 다른 글
| Amazon EBS(Elastic Block Store) 에 대한 정리 (3) | 2019.10.31 |
|---|---|
| AWS 의 Auto Scale 에 대한 정리 및 사용 (0) | 2019.08.25 |
| 클라우드 아키텍처(Cloud Architecture) 를 설계할 때 고려할 5가지 (5 Pillars) (0) | 2019.08.09 |
| AWS 자격증명(Credential) 과 IAM에 대한 기본정리 (0) | 2018.10.02 |
| AWS의 RDS에 대하여 (0) | 2018.09.11 |