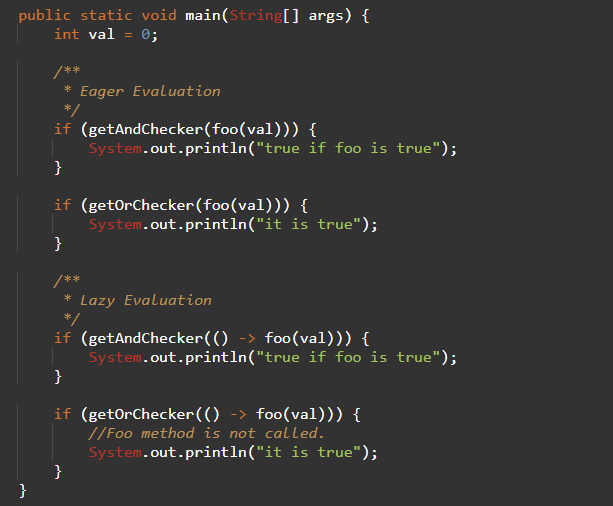
프로그램 언어를 해석하고 실행시키는 대표적인 방법으로 Compile 과 Interpret 방식이 있다.
Compile 작업은 Compiler 에 의해 실행되고, Interpret 작업은 Interpreter 에 의해 실행되는데, 두 컨셉이 명확하게 다르기 때문에
많은 프로그래밍 언어들은 둘 중 한가지 방식을 통해 언어를 실행하도록 설계된다. (Java 와 같이 두가지를 모두 채용하는 경우도 있다!)
그렇기 때문에 Compiler 와 Interpreter 를 이해하는 것은 어떤 언어를 배우던지간에 해당 언어의 구동원리를 배울 수 있는 중요한 선행학습이라할 수 있겠다.
컴파일 (Compile)
프로그래밍 언어를 Runtime 이전에 기계어로 해석하는 작업 방식이다.
이때 원래의 소스를 원시 코드, 바뀐 코드를 목적 코드(Object Code) 라 한다.
런타임 이전에 Assembly 언어로 변환하기 때문에 구동 시간이 오래걸리지만, 구동된 이후는 하나의 패키지로 매우 빠르게 작동하게 된다.
구동시에 코드와 함께 시스템으로부터 메모리를 할당받으며 할당받은 메모리를 사용하게 된다.
런타임 이전에 이미 해석을 마치고 대게 컴파일 결과물이 바로 기계어로 전환되기 때문에 OS 및 빌드 환경에 종속적이다.
그러므로 OS 환경에 맞게 호환되는 라이브러리와 빌드환경을 구분해서 구축해줘야 한다.
Compile 언어의 대표격으로 C / C++ 와 같은 언어들을 들 수 있으며, Java 역시 Byte Code 로 바꾸기 위한 과정에서 컴파일을 수행한다.
인터프릿 (Interpret)
런타임 이전에 기계어로 프로그래밍 언어를 변환하는 컴파일 방식과 다르게, 런타임 이후에 Row 단위로 해석(Interpret) 하며 프로그램을 구동시키는 방식이다.
프로그래밍 언어를 기계어로 바로 바꾸지않고 중간 단계를 거친 뒤, 런타임에 즉시 해석하기 때문에 바로 컴팩트한 패키지 형태로 Binary 파일을 뽑아낼 수 있는 Compile 방식에 비해 낮은 퍼포먼스를 보이게 된다.
런타임에 직접 코드를 구동시키는 특징이 있기 때문에 실제 실행시간은 느리며, 대신 런타임에 실시간 Debugging 및 코드 수정이 가능하다.
또한 메모리를 별도로 할당받아 수행되지 않으며, 필요할 때 할당하여 사용한다. 이와 관련되어 코드의 흐름 자체도 실제 필요할 때, 실제 수행되어야하는 시점에 수행되기 때문에 덕타이핑(Duck Typing) 이 가능한 측면이 있으나, 반대로 정적 분석이 되지않는 Trade off 를 갖고 있다.
대표적인 Interpreter 언어로는 Javascript 와 같은 스크립팅 언어들이 있다. 하지만, 스크립트 언어 뿐 아니라 컴파일 이후의 동작에서 Interpret 을 수행하는 언어들도 많이 존재한다.
많은 프로그래밍 언어들의 인터프리터는 해석을 위한 Virtual Machine 을 두고, Machine 위에서 Interpret 을 수행하게 되는데, 이 때 해석의 기반이 되는 머신들이 OS 환경들을 지원해줌으로써, 해당 방식으로 인터프리터는 OS 및 플랫폼 에 종속되지않는 프로그램 구동이 가능하게 된다.
(이런 특징을 지닌 Interpreter 는 Java 의 JVM 과 Python 의 Analyzer 가 있겠다.)
컴파일러와 인터프리터의 차이는 잘 이해하고 언어와 환경을 파악하는데 활용하는 것이 중요하다.
'Computer Base > Computer Engineering' 카테고리의 다른 글
| 가십 프로토콜 (Gossip Protocol) 이란? (0) | 2022.05.15 |
|---|---|
| 네트워크 포트 미러링(Port Mirroring) 에 대하여 (0) | 2019.10.18 |
| 간략하게 정리해보는 OLTP / OLAP 의 개념 (0) | 2019.08.07 |
| CIDR (사이더) 기법에 대한 정리 (0) | 2019.08.06 |
| Software Oriented Architecture(SOA) 의 정의와 Micro Service Architecture (0) | 2019.05.12 |