분산 환경의 처리는 일반적인 환경의 구성과 많이 다르며 분산시스템의 특이성에 대한 개념들이 있다.
특히나 자주 듣게 되는 단어 중 하나는 결과적 일관성(Eventual Consistency) 라는 개념으로, 분산 시스템(Distributed System) 을 운영하게 되면 흔치않게 접하게 된다.
이는 개념과 관련된 이론이 그만큼 중요한 내용임을 반증한다.
먼저 예로 들은 Eventual Consistency 에 대해 설명하자면 이는 분산 컴퓨팅(Distributed Computing) 에서 고가용성(High Availability)을 보장하기 위한 방법의 하나로
"주어진 데이터에 대한 변경이 없다면 해당 Element 에 대한 모든 Access 는 가장 최근에 변경된 내용을 가리킨다" 는 정의를 말한다.
분산 시스템에서 데이터를 조회할 때 모든 시스템이 동일한 데이터를 가질 수 있다고 보장할 수는 없으며 결과적 일관성은 어느 시점에는 데이터가 다를 수 있지만, 결국에는 모든 시스템이 최신의 데이터를 가질 수 있도록 보장된다는 내용이다.
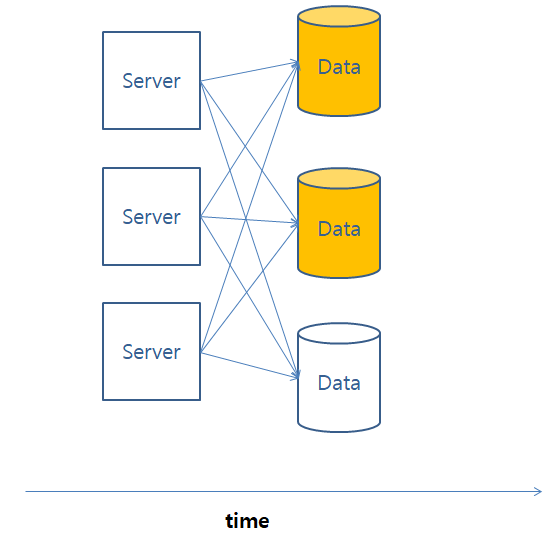
이는 BASE 원칙의 일종으로 분류되기도 한다. BASE 원칙이란 다음의 원칙들이 포함된다.
- Basically Available : 일반적인 Read / Write 에 대한 동작이 "가능한만큼" 지원된다.
(여기서 가능한만큼 이라 함은, 동작이 가능하나 Consistency 에 대한 보장이 되지않는다는 점이다.)
- Soft state : Consistency 가 보장되지 않기 때문에 상태(State) 에 대해 Solid 하게 정의하지 못하다.
- Eventually consistent : 위에 언급된 Eventual Consistency 개념에 따라 충분한 시간이 흐르면 모든 시스템 환경 내에서 데이터는 최신의 데이터가 보장된다.
BASE 원칙은 전통의 트랜잭션 시스템을 위한 ACID 원칙에 반대된다. 이는 분산 환경에서 나타나는 특징이기 때문이다.
이러한 특징에 대해 CAP Theorem 은 다음 3가지 조건을 모두 만족하는 분산 시스템을 만드는 것이 불가능함을 정의한다.
- 일관성(Consistency) : 모든 시스템의 데이터는 어떤 순간에 항상 같은 데이터를 갖는다.
- 가용성(Availability) : 분산 시스템에 대한 모든 요청은 내용 혹은 성공/실패에 상관없이 응답을 반환할 수 있다.
- 내구성(Partition Tolerance) : 네트워크 장애 등 여러 상황에서도 시스템은 동작할 수 있다.
분산환경 특징 상 3가지 성질을 모두 만족할 수는 없고, 일반적으로 다음과 같이 선택된다.
- CP (Consistency & Partition Tolerance) : 어떤 상황에서도 안정적으로 시스템은 운영되지만 Consistency 가 보장되지 않는다면 Error 를 반환한다. (어떤 경우에도 데이터가 달라져서는 안된다.)
이는 매 순간 Read / Write 에 따른 정합성이 일치할 필요가 있는 경우 적합한 형태이다.
- AP (Availability & Partition Tolerance) : 어떤 상황에서도 안정적으로 시스템은 운영된다. 또한 데이터와 상관없이 안정적인 응답을 받을 수 있다. 다만 데이터의 정합성에 대한 보장은 불가능하다. (특정 시점에 Write 동기화 여부에 따라 데이터가 달라질 수 있다.)
이는 결과적으로는 일관성이 보장된다는 Eventual Consistency 를 보장할 수 있는 시스템에 알맞는 형태이다.
서버시스템 및 분산시스템에 있어서 핵심적인 개념이므로 잘 정리해두고 아키텍처를 고려할 때 항상 생각해두자
'Computer Base > Computer Science' 카테고리의 다른 글
| 컨텍스트 스위치(Context Switching) 에 대한 정리 (2) | 2019.06.02 |
|---|---|
| 컴퓨터가 시간(Time) 을 다루는 방법 (0) | 2018.12.26 |
| Nagle Algorithm (네이글 알고리즘) 에 대한 정리 (0) | 2018.10.19 |
| 인터넷이 어떻게 동작하는가(How internet works) (0) | 2018.10.15 |
| OSI 7계층(OSI 7 Layer) 에 대한 정리 (0) | 2018.08.22 |