CSR (Client Side Rendering) 이니 SPA (Single Page Application) 과 같은 내용들은 10년도 지난 개념들이지만, 시장이 변하는건 그렇게 빠르지 않다.
많은 웹 서비스들이 아직 SSR (Server Side Rendering) 기반으로 백엔드와 프론트엔드를 관리하고 있으며 아키텍처를 어떻게 디자인하는 것이 좋은지는 장단점이 있는 중요한 설계 포인트 중 하나가 된다.
특히 팀의 개발 환경 구성 및 전체적인 설계도를 구상해야하는 시니어 개발자 및 Tech Lead 라면 사용 사례를 잘 분석하고 알맞은 접근 방법을 택하는 것이 중요해진다.
이번 포스팅에서는 CSR 기반의 Single Page Application 을 위한 프론트엔드 개발 파이프라인을 알아본다.
여전히 Java 와 Spring 환경은 주류이지만, 이 환경이 지배적이던 수 년 전에는 프론트엔드 코드가 백엔드 어플리케이션과 같이 묶여서 개발되어지고 배포되어지는 SSR (Server Side Rendering) 방식이 대부분이었다.
이렇게 되면 개발 환경이 분리되지 않기 때문에 역할 분리나 협업에 있어서 애로 사항들이 발생하고, 무엇보다도 하나의 WAS 가 프론트엔드 & 백엔드를 모두 서비스하게 되다보니 배포도 같이 일어나며 인프라 비용의 비효율성도 생기게 된다.
백엔드의 버그가 생겼는데 프론트엔드 코드까지 재빌드가 되어야하거나, 프론트엔드는 리소스를 거의 잡아먹지 않는데 백엔드가 리소스를 많이 잡아먹어서 Scaling 을 해야하는 경우를 생각해보면 이해가 빠를 것이다.
무튼.. 이러저러한 애로사항이 있던 와중에 밀결합(Decoupling)의 개념이 세계적으로 대세가 되며 프론트엔드와 백엔드가 분리되어 각자의 라이프사이클을 가지며, API 를 통해 통신하는 CSR 방식이 점차 확산되어졌다.
CSR 방식에서는 프론트엔드와 백엔드가 물리적으로 분리되기 때문에 인프라를 각자 관리할 수 있으며 개발 환경이 나뉘어지기 때문에 역할 분리 및 작업의 비효율성이 개선되어질 수 있다.
그렇다면 Client Side Rendering 을 위한 아키텍처 설계는 어떻게 이뤄질까?
먼저 동적 코드에서 정적 코드가 분리된다는 점에 주목해야한다.
기존에 프론트엔드는 Javascript 가 동적 로직을 처리하기는 하지만 기본적으로 클라이언트 브라우저에서 동작한다는 측면 때문에 정적 리소스 (Static Resource) 로 분류되어진다.
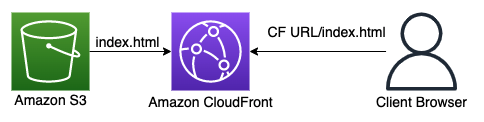
이와 같은 정적 리소스들은 인터넷에서 접근될 때 클라이언트 브라우저가 "다운로드" 하여 "실행" 하는 방식이기 때문에 웹 기반의 스토리지에서 제공되어질 수 있다.
이 말은 웹 서버만으로도 정적 리소스는 제공될 수 있으며, 당연히 CDN 을 통한 가속화도 가능하다는 것이다.
예전에는 웹 서버 스택을 nginx, apache 위에서 로드밸런싱을 구축해서 제공을 했었지만 클라우드 환경이 대세가 되면서 이 역시 Amazon S3 와 같은 웹 기반의 스토리지로 옮겨가게 되었다. 그리고 이런 정적 웹사이트는 Amazon CloudFront 와 같은 CDN 을 통해 사용자 더 가까운 위치에서 제공될 수 있게끔 디자인이 되게 된다.
위와 같이 구성 시 사용자는 CDN 을 통해 전세계 어디에서든 빠르게 정적 리소스를 접근할 수 있으며, 해당 리소스의 렌더링을 받을 수 있다. 또한 S3 와 같은 스토리지는 내구성이나 가용성을 AWS 에서 관리해주기 때문에 개발자 입장에서는 nginx 환경 구성이나 Auto Scaling 을 직접 구축할 필요없이 최소한의 노력으로 서비스를 구축할 수 있게 된다.
특히 위와 같은 구조는 동적인 처리가 적게 요구되는 마케팅 페이지 등에서 많이 활용하는 아키텍처이기도 하다.
그러면 위와 같은 변경된 구조에서 코드의 배포는 어떻게 수행해야할까?
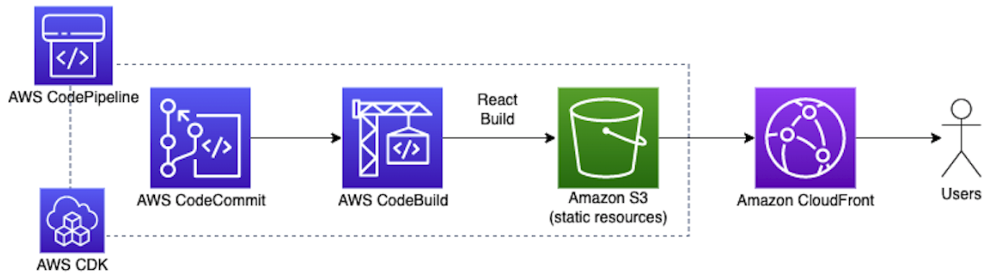
전통적인 환경에서는 Jenkins 등을 통해 백엔드와 프론트엔드가 전체 빌드된 이후 서버 머신들 위에 직접 배포되었지만, 위와 같은 경우에는 머지된 코드가 단순히 Amazon S3 라는 오브젝트 스토리지 위에 배포되기만 하면 된다. 다만 React 와 같이 프론트엔드 코드를 빌드해주는 경우, 이에 대한 작업 구성은 별도로 필요해진다.
AWS 의 CodePipeline 은 위의 배포를 지원하며, 코드 저장소에서 작업한 코드가 Merge 되면 자동으로 S3 에 빌드가 배포되게 구성할 수 있다.
다음 샘플은 AWS 의 Infra As A Code 툴인 AWS CDK 를 이용해서 위의 파이프라인을 만들어놓은 샘플이다.
CDK 를 구동하기만 함으로써 쉽게 AWS 를 활용해서 정적 페이지의 구성과 개발을 위한 파이프라인을 만들어 볼 수 있다.
React 기반으로 어플리케이션을 배포하는 프론트엔드 파이프라인이 만들어져있기 때문에 React 개발 및 배포 환경 구성이 필요할 때 참고해볼 수 있을 것 같다.
CSR 이 무조건적인 장점만 있는 것은 아니며, SEO (Search Engine Optimization, 검색 엔진 최적화) 에 있어서 불리한 측면이나 작업 완료 시간이 SSR 에 비해 느리다는 점 등이 단점으로 뽑히며, 현재 두 개념은 적절히 혼합되어 사용 사례에 알맞게 사용되고 있다고 볼 수 있다.
클라우드 환경에서 분산처리를 위한 아키텍처를 설계한다면, AWS 의 Load Balancer 를 이용해볼 수 있다.
Amazon Web Service 가 Provisioning 하는 Load Balancer 는 ELB(Elastic Load Banacing) 서비스라 하며, 기본적으로 Logging, Cloud Watch 를 통한 지표, 장애 복구, Health Check 와 같은 기능들을 제공한다.
ELB 서비스의 종류로는 2019년 8월 기준으로 3가지 종류가 있다.
(1) Classic Load Balancer
가장 기본적인 형태이자 초기에 프로비저닝되던 서비스로, 포스팅 등에 나오는 설명에 단순히 ELB 라고 나와있으면 Classic Load Balancer 를 말하는 경우가 많다.
L4 계층부터 L7 계층 까지 포괄적인 로드밸런싱이 가능하며, 따라서 TCP, SSL, HTTP, HTTPS 등 다양한 형태의 프로토콜을 수용할 수 있고 Sticky Session 등의 기능도 제공해준다.
특징적으로 Classic Load Balancer 는 Health Check 를 할 때, HTTP 의 경우 /index.html 경로를 참조한다.
즉, 웹서버 인스턴스의 경로에 /index.html 가 포함되어있지 않다면(404) Health Check 를 실패한다는 뜻이다...
따라서 이럴 때에는 Health Check 를 위한 프로토콜만 TCP 로 바꾸고 포트만 80 으로 체크하게 하는 방법이 있다.
중요한 특징으로... CLB 는 로드밸런서가 url 하나를 가질 수 있다. 즉, CLB 로 매핑되어있는 인스턴스들은 무조건 하나의 URL 을 통해 접근하게 된다.
(2) Application Load Balancer
Classic Load Balancer 이후 출시된 서비스로 HTTP 및 HTTPS 트래픽 로드밸런싱에 최적화되어있다.
L7 계층에서 작동하며 Micro Service Architecture 와 같은 Modern 환경을 겨냥한 많은 강점들이 있는데, WebSocket 이나 HTTP/1.1 이상의 프로토콜에 대한 지원, 향상된 라우팅 정책과 사용자의 인증 까지도 지원을 해준다.
웹서비스를 목적으로 한다면 기존 Classic Load Balancer 가 갖고 있던 장점 이상의 강점들을 많이 포함하고 있다.
단 L7 계층에서 작동하기 때문에 TCP 등에 대한 밸런싱은 지원되지 않는다.
직접 사용해서 구축 할때에 Classic Load Balancer 에 비해 좀 더 구축이 편하고 웹서버 밸런싱에 있어서는 확실히 다양한 옵션이 있다. Health Check 경로 또한 지정할 수 있으며, 기본이 / 로 정해져있다.
CLB와 다르게 ALB 는 host-based Routing 과 path-based Routing 을 지원한다. Content Based Routing 이라고도 하며 ALB 에 연결된 인스턴스들은 여러개의 URL 과 path 를 가질 수 있다.
(3) Network Load Balancer
Load Balancer 중 성능적으로 최적의 로드밸런싱을 지원한다. TCP, UDP 등의 서버를 구축할 때 해당 프로토콜 들에 대해 굉장히 낮은 지연 시간으로 최적의 성능을 보여준다고 한다.
사용해본적이 없는데... 사용해본다면 좀 더 포스팅 내용을 보강해야겠다.
로드밸런서에 EIP 를 직접 붙일 수는 없고, 필요하다면 DNS 의 도메인 네임 대신 CNAME 을 사용하거나 Route53 서비스와 같이 사용해야 한다. 그 이유는... ELB 역시 서버이기 때문에, 부하 상황에서 오동작의 위험이 있고 그에 따라 자체적으로 Scale In - Scale Out 을 수행하기 때문이다. (즉, IP 를 지정할 서버가 한대가 아니게 될 수 있다.)
또한, ELB 는 Multi-AZ 환경에서 "내부적으로는" 각 Availability Zone 별로 구성된다. 이 때 트래픽의 분배는 AZ 당 ELB 사정에 맞게 분배되므로... Multi AZ 환경에서는 각 Availability Zone 별 인스턴스의 숫자를 동일하게 맞춰주는 것이 좋다. (동일하게 맞추지 않으면 특정 Zone 의 인스턴스들에 트래픽이 몰릴 수 있다.)
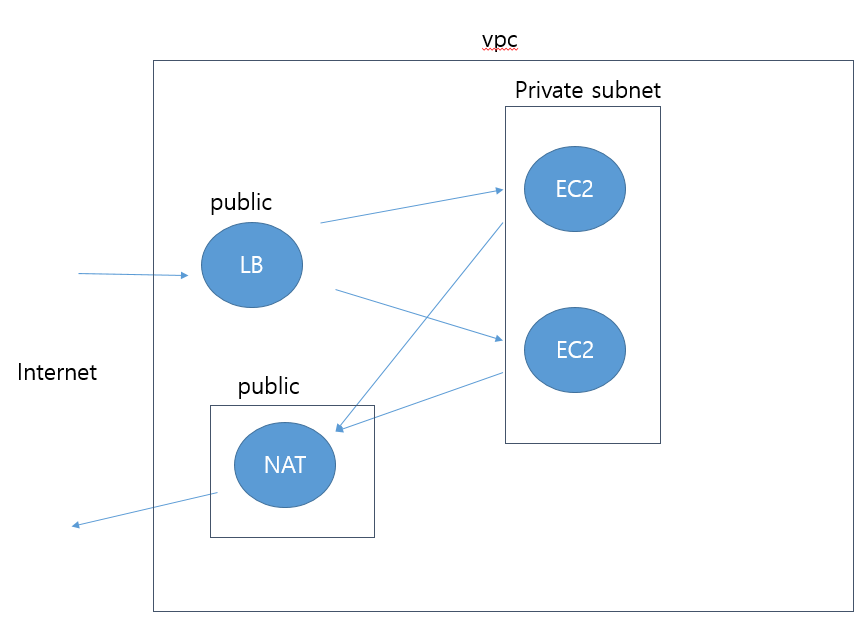
로드밸런서를 통해 Cloud 환경에서 아키텍처를 설계할 때에는 Private Subnet 들에 EC2 인스턴스들을 배치해둔 상태에서, ELB로 트래픽을 연결할 수 있도록 인스턴스들을 연결시켜주고, Public 영역에 위치시켜 놓는 식으로 구성을 한다.
혹은, ELB 자체는 VPC 내부에 형성시켜 두고, ELB로 들어온 트래픽을 Private Subnet 으로 전개시켜주며, 인터넷에 연결을 위한 Public NAT 를 두고 출력을 해당 NAT 를 거치게 하는 방식도 있다.
변경관리 및 자동화, 이벤트 응답, 일상적인 운영의 성공적인 관리 와 같은 항목들이 고려되어야 한다.
Operational Excellence 를 위한 다음과 같은 원칙들이 있다.
- Perform operations as code : Cloud 환경에서도 일반 어플리케이션 코드를 만들 때처럼 작업의 프로시저와 이벤트에 대한 동작을 구현해야 한다. 휴먼 에러를 배제하고 이벤트 중심으로 구동되게끔 설계해야 한다.
- Annotate documentation : 매빌드 이후에 Document 를 만들도록 자동화시키는 것이 중요하다. Cloud 환경에서는 documentation 을 자동화시킬 수 있다.
- Make frequent, small, reversible changes : Component 들의 주기적 업데이트를 가능하게 하고, 실패 시 Rollback 이 가능해야 한다.
- Refine operations procedures frequently : 주기적으로 프로세스를 향상시킬 방법을 고안해야 한다.
- Anticipate failure : 프로세스가 실패로 이어질 상황을 시뮬레이션 해보는 것이 필요하다.
- Learn from all operational failures : Operation failure 에 대해 정리하고 학습해야 한다.
* Operational Excellence 를 위해 AWS Config 를 통해 테스트를 준비하고, Amazon CloudWatch 를 통해 모니터링하며, Amazon ES(Elastic Search Service) 를 통해 로그를 분석하는 것이 좋다.
2. 보안(Security)
정보 및 시스템을 보호하는 중점가치이다.
데이터 기밀성 및 무결성, 권한 관리를 통한 사용자 작업 식별 및 관리, 시스템 보호와 보안 이벤트 제어와 같은 항목들이 고려되어야 한다.
Security 요소를 위해 다음과 같은 원칙들이 있다.
- Implement a strong identity foundation : 최소 권한의 원칙과 의무에 대한 권한을 AWS Resources단위로 부여한다.
- Enable traceability : 모든 동작은 모니터링과 알람이 가능하게끔 해야한다. 로그 시스템을 통합시켜놓음으로써 자동화가 가능하다.
- Apply security at all layers : 모든 계층에 보안 요소를 포함시킨다. (edge network, VPC, subnet, Load Balancer, instances, OS, application)
- Automate security best practices : Security mechanism 을 자동화시킨다. 버전관리를 하듯 템플릿을 관리한다.
- Protect data in transit and at rest : 데이터에 대해서도 Encryption, Tokenization, Access control 등을 적용한다.
- Prepare for security events : 갑작스런 보안 사고에 대비해 simulation 해보고, 탐지 속도, 탐지력, 복원력 을 측정해보는 것이 좋다.
* Security 를 위해 IAM, CloudTrail(API Call 추적), Amazon VPC, Amazon CloudFront(CDN 데이터의 보안), 데이터 보안을 위한 RDS, S3, AWS KMS(Key management system), CloudFormation / CloudWatch(시뮬레이션 및 모니터링) 등을 이용하는 것이 좋다.
3. 안정성(Reliability)
비즈니스 및 고객 요구를 충족시키기 위해 장애를 예방하고 신속하게 복구할 수 있는 능력에 중점을 둔다.
기본요소, 복구계획 및 변경 처리와 같은 항목들이 고려되어야 한다.
Reliability 를 위해 고려해야할 원칙들은 다음과 같다.
- Test recovery procedures : System fail 및 fail 에 대한 recovery 상황을 테스팅하고 전략을 수립할 수 있기 때문에, 시나리오에 알맞게 recover 동작을 테스트해보는 것이 필요하다.
- Automatically recover from failure : Key Performance Indicator(KPI) 를 모니터링함으로써 이상상태에 대한 Threshold 값을 세팅할 수 있고 복구를 자동화할 수 있다.
- Scale horizontally to increase aggregate system availability : Horizontal scaling 은 Single Failure 가 전체 시스템에 영향이 미치지않게끔 구성할 수 있게 한다. 구조를 수평적으로 작게 나누고 합치는 형태의 구조를 사용한다.
- Stop guessing capacity : 온프레미스 환경의 흔한 오류 원인은 Resource 포화상태이다. 클라우드 환경에서는 Load 를 모니터링하고 System utilization 을 통해 Provisioning 을 자동화할 수 있다. (Under/Over provisioning 의 방지)
- Manage change in automation : 인프라 구성의 변화는 자동화되어야 한다.
* 사용가능한 AWS 서비스들로 AWS IAM, AWS CloudTrail, AWS Config, AWS CloudFormation, AWS KMS 등의 서비스가 있다.
4. 성능 효율성(Performance Efficiency)
IT 및 컴퓨팅 리소스를 효율적으로 사용하는데 중점을 둔다.
요구사항에 적합한 리소스 유형 및 크기, 성능 모니터링 정보를 바탕으로 한 효율성 유지와 같은 항목들이 고려되어야 한다.
Performance Efficiency 를 위해 고려해야할 원칙들은 다음과 같다.
- Democratize advanced technologies : 새로운 기술이 있을 때, 클라우드 환경에서는 쉽게 적용시킬 수 있다.
- Go global in minutes : Multiple Region 에 몇번의 클릭만으로 배포가 가능하다. 이는 고객 입장에서도 적은 비용으로 만족감을 느낄 수 있는 서비스의 특성이 된다.
- Use serverless architecture : 클라우드의 서버리스 아키텍쳐는 서버를 직접 구동하고 운용할 필요성을 크게 줄여준다.
- Experiment more often : 가상의 자동화된 환경에서 테스트는 좀 더 빠르게 이루어질 수 있다.
- Mechanical sympathy : 기술적 접근 방법을 고려한다.
* Performance Efficiency 를 위해, Auto Scaling, Amazon EBS, Amazon RDS, Amazon Route53, ElastiCache, CloudFront 와 같은 서비스들이 활용될 수 있다.
5. 비용 최적화(Cost Optimization)
불필요한 비용의 발생을 방지하고 지출 내용을 파악하여 가장 적합한 수의 적절한 리소스 사용에 초점을 둔다.
지출분석을 통해 초과비용 없이 비즈니스 요구사항을 만족시키는 조정 항목들이 고려되어야 한다.
Cost Optimization 을 위해 다음 원칙들이 고려되어야 한다.
- Adopt a consumption model : 필요한 만큼의 컴퓨팅 리소스에 대해서만 비용이 지출되어야 하고 비즈니스 요구에 따라 사용량이 조절되어야 한다. (예측해서 많이 잡거나 해서는 안된다.)
- Measure overall efficiency : 비즈니스의 전체 workload 와 output 을 측정해야 한다.
- Stop spending money on data center operations : 인프라 관리비용 자체에 돈을 더 쓰면 안된다.
- Analyze and attribute expenditure : Cloud 환경에서는 시스템의 사용량을 조회하고 비용을 산정하기 쉽다. ROI 를 측정하고 Resource 를 최적화하자.
- Use managed services to reduce cost of ownership : Cloud 환경을 이용하면 email 을 보낸다던지하는 운영의 비용이 감축된다.
* AWS Cost Explorer 를 사용해서 비용 산정량을 확인할 수 있다. AWS Budget 은 사용량에 따라 향후 사용량을 예측할 수 있게 지원한다.
또한 Resource 를 Amazon Aurora 와 같은 것을 사용하면 라이센스 비용을 절감할 수 있고, Auto Scaling 은 스케일링의 효율성을 증가시켜준다.
실 서비스의 아키텍처를 구조화할 때도 반드시 고려해야할 부분이고, 이 결정은 실제로 서비스에 큰 영향을 주게 된다.
가령 사용자가 갑자기 증가할 경우, 엄청난 수의 요청에 대한 처리를 어떻게 할 것인가는 Backend 에서 가장 중요하게 고려해야할 부분 중 하나이다.
Scaling 의 방법에는 크게 Scale Up 과 Scale Out 이 존재한다.
Scale Up: 서버 자체의 Spec 을 향상시킴으로써 성능을 향상시킨다. Vertical Scaling 이라 불리기도 한다. 서버 자체의 갱신이 빈번하여 정합성 유지가 어려운 경우(주로 OLTP 를 처리하는 RDB 서버의 경우) Scale Up 이 효과적이다.
성능 향상에 한계가 있으며 성능 증가에 따른 비용부담이 크다. 대신 관리 비용이나 운영 이슈가 Scale Out 에 비해 적어 난이도는 쉬운 편이다. 대신 서버 한대가 부담하는 양이 많이 때문에 다양한 이유(자연 재해를 포함한다...)로 서버에 문제가 생길 경우 큰 타격이 불가피하다.
Scale Out: 서버의 대수를 늘려 동시 처리 능력을 향상시킨다. Horizon Scaling 으로 불린다. 단순한 처리의 동시 수행에 있어 Load 처리가 버거운 경우 적합하다. API 서버나, 읽기 전용 Database, 정합성 관리가 어렵지않은 Database Engine 등에 적합하다.
특히 Sharding DB 를 Scale Out 하게 된다면 주의해야하는데, 기존의 샤딩 알고리즘과 충돌이 생길 수도 있고(샤드가 갯수에 영향을 받을 경우...) 원하는 대로 부하의 분산이 안생길 수 있으니 각별히 주의할 필요가 있다.
스케일 아웃은 일반적으로 저렴한 서버 여러 대를 사용하므로 가격에 비해 뛰어난 확장성 덕분에 효율이 좋지만 대수가 늘어날 수록 관리가 힘들어지는 부분이 있고, 아키텍처의 설계 단계에서부터 고려되어야 할 필요가 있다.
요즘은 클라우드를 사용하기 때문에 Scaling 에 있어서 큰 이점이 있으며, 서비스의 목표치에 알맞게 Scalability 를 설계하고 두 스케일링 방법을 모두 적용시키는 것이 일반적이다.