구글 Protobuf 는 강력한 데이터구조이며 환경간 이식성이 뛰어나고 패킷으로 사용할 때, 자체의 성능(통신 속도 및 작은 패킷 크기)이 뛰어나지만, 정해진 형식이 있다보니 사용에 있어서 알아두어야할 점들이 몇가지 있다.
실무에서 사용하면서 알아두어야 했던 점들 및 특징적인 점들 몇가지를 정리해보았다.
1. protobuf 는 패킷간 상속과 추상화를 지원하지않는다.
프로토버프를 도입하기 가장 꺼려지는 이유인데, protobuf 의 Data Structure는 상속과 추상화와 같은 생산성을 위한 개발자들의 구조를 부정한다.
Protobuf 는 애초에 범용(?) 목적으로 설계되었다기 보다는 확실한 단일 목적에 대해 Compact 하게 설계된 Data Structure 이다.
즉, 확실히 의미를 갖는 필요한 데이터만 저장할 수 있게 되어있으며, 그렇기 때문에 Stream 으로 사용할 시 필요한 정보만 주고받는 효율성을 이점으로 취할 수 있는 반면, 데이터를 담는 데 있어서 유연하지 못하다.
그렇기 때문에 프로토콜 버퍼를 패킷으로 통신을 해야 한다면 모든 패킷에 필요한 정보들을 분류해서 정의해주는 것이 필요하다.
2. protobuf 의 패킷 넘버링은 생각보다 엄격하지않다. 하지만 패킷의 순서는 매우 중요하다.
다음과 같은 에러 처리를 위한 프로토콜 버퍼 Data Structure가 있다고 가정해보자.
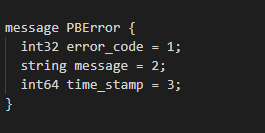
위의 데이터 구조에서 time_stamp 패킷의 넘버링을 4로 바꿔도 무방하다. 프로토콜 버퍼에서 구조 내에서 중요한 것은 패킷들의 순서를 지키는 일이다.
다만, Protocol Buffer 를 enum 형태로 정의해서 쓰는 경우라면 조금 얘기가 다른데,

위와 같은 Enum 패킷에서는 numbering 이 의미를 갖는다. enum 의 경우 넘버링이 Enum 클래스의 ordinal 과 동치되기 때문에, Compile 해서 사용할 경우 패킷이 다르다면 예기치 못한 에러가 발생할 수 있다.
3. Protobuf 구조가 프로토콜로 정해졌다면 데이터 구조는 변경하지 않는 것이 좋다.
통신에 있어서 Protobuf 를 사용하는데, 기존 데이터 구조가 삭제 또는 변경된다면 그 구조를 삭제 & 변경하는 것이 아니라 새로 패킷을 추가하는 편이 좋다.
그 이유는 하위호환성 때문으로, 통신하는 양쪽의 Protobuf 빌드가 항상 동기화가 완벽하다면 문제가 없지만, 개발을 하다보면 버전이 달라질 수밖에 없다.
이 때 문제를 방지하기 위해 데이터 구조의 크기를 늘리는 방법을 선택해야 한다.
하지만 패킷의 크기가 커질지는 염려하지 않아도 된다. Protobuf 의 특징 상 입력되지않는 패킷은 보내지않도록 퍼포먼스 측면에서 최적화가 지원된다.
4. 구글이 지원해주는 protobuf 라이브러리가 있으며, 이를 사용하면 프로토버프의 사용이 매우 편리해진다.
다음 링크를 참조하자.
https://github.com/protocolbuffers/protobuf
protocolbuffers/protobuf
Protocol Buffers - Google's data interchange format - protocolbuffers/protobuf
github.com
protobuf 라이브러리는 언어별로 필요한 기능들을 유틸리티 형태로 지원한다.
아주 방대하니 전체를 쓸 생각보다는 환경에 맞게 필요한 만큼만 모듈을 가져다 쓰는 것이 좋다.
또한 protobuf 라이브러리에는 proto 파일 내에서 사용할 수 있는 공통 protobuf 형식들도 정의되어 있으므로 참고하는 것이 좋다.
가령 proto 파일 내에서 Collection 이나 timestamp 등의 기능을 사용할 수 있도록 정리되어있다.
5. 당연한 얘기지만 proto 파일의 주석조차 compile 결과로 빌드된 소스에 포함 된다.
만약 소스 자체로 어떤 스크립트가 실행되어야 한다면 환경에 주의하자.
주석에 한글 특수문자가 포함된 proto 파일을 자동화 스크립트로 돌리다가 문제가 생기는 일이 더러 있었다.
프로토콜 버퍼는 구글이 지원하고 있는 직렬화방식이고 강력하며 쓰임새도 다양하다.
하지만 현재로써는 아는만큼 사용할 수 있는 도구임이 분명하다. 사용에 있어 유의하고 항상 공식 지원을 참고하는 것이 좋겠다.
'Computer Base > Computer Engineering' 카테고리의 다른 글
| CIDR (사이더) 기법에 대한 정리 (0) | 2019.08.06 |
|---|---|
| Software Oriented Architecture(SOA) 의 정의와 Micro Service Architecture (0) | 2019.05.12 |
| Access performances in Computer (0) | 2019.05.06 |
| Method 와 Function 의 차이에 대한 이해 (0) | 2019.02.26 |
| Cache 에 대한 이론적인 정리 (0) | 2019.02.20 |



