JVM 은 Java 코드 및 Application을 동작시킬 수 있도록 런타임 환경을 제공해주는 Java Engine 이다.
JVM 은 JRE의 일부분이며 Java 개발자로서 JVM 의 동작을 이해하는 것은 Java 구동 환경과 JRE(Java Runtime Environment) 을 이해하는 데 있어서 아주 중요한 부분이다.
Java 가 추구하는 가치는 WORA(Write Once Run Anywhere) 이며, 이는 모든 자바의 코드는 JVM 이라는 환경 위에서 동작하면서 어느곳이든 이식이 가능하다는 뜻을 포함하고 있다.
먼저 JVM 의 아키텍처는 다음과 같다.
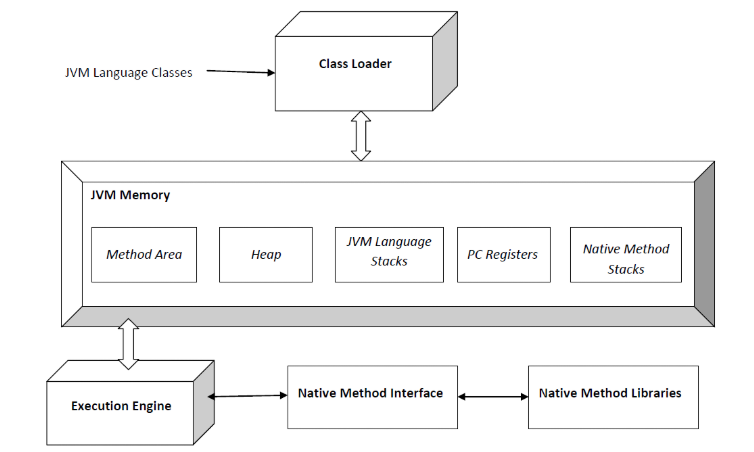
하나하나 동작을 살펴보도록 하자.
Java Application 의 동작은 다음과 같은 순서로 이루어진다.
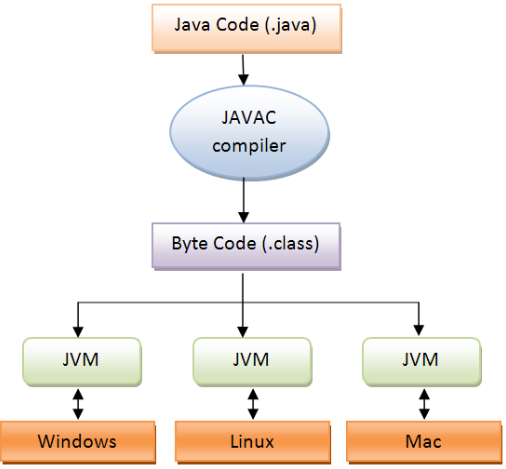
(1) Java JIT Compiler 가 Java 코드를 해석한다. Java Compiler 는 해석한 .java 코드를 .class 파일 형태로 해석결과로 만든다.
(2) 클래스 로더에 의해 .class 파일들은 다음 단계들을 거치며 해석된다.
- Loading : 클래스 파일에서 클래스 이름, 상속관계, 클래스의 타입(class, interface, enum) 정보, 메소드 & 생성자 & 멤버변수 정보, 상수 등에 대한 정보를 로딩해서 Binary 데이터로 변경한다.
- Linking : Verification 과 Preparation, Resolution 단계를 거치면서 바이트코드를 검증하고 필요한 만큼의 메모리를 할당한다. Resolution 과정에서는 Symbolic Reference 를 Direct Reference 등으로 바꿔준다.
- Initialization : static block 의 초기화 및 static 데이터들을 할당한다. Top->Bottom 방식으로 클래스들을 해석한다.
(3) 컴파일된 바이트코드는 Execution Engine 에 의해 머신별로 해석된다. 이제 Host System 과 Java Source 는 Byte Code 를 이용해 중계된다. JVM 이 할당된 메모리 영역을 관리하게 된다.
Execution Engine 은 3가지 파트로 구성된다.
- Interpreter : 바이트코드를 Line by Line 으로 해석하고 실행시킨다. 동일 메서드가 여러번 Call 되더라도 매번 Interperter 가 호출된다.
- JIT compiler(Just In Time Compiler) : Interpreter 의 효율성을 증가시켜준다. 모든 Byte 코드를 한번에 Compile 해놓고 Direct 로 변환할 수 있게 해줌으로써 Re-interpret 의 발생을 낮춰준다.
- Garbage Collector : Un-referenced Object 들을 제거해주는 가비지 컬렉팅을 수행한다.
이처럼 일반적인 C 프로그램과 다르게 Java 는 ByteCode 로 해석하고 변환하는 단계가 있기 때문에 느릴 수 밖에 없다.
- Dynamic Linking : Java 의 Linking 은 런타임에 동적으로 일어난다.
- Run-time Interpreter : Byte Code 의 머신코드로의 컨버팅 역시 Runtime 에 일어난다.
물론 최신 Java 버전은 병목현상을 효과적으로 제거했기 때문에 구버전의 자바와는 비교가 안될정도의 퍼포먼스를 갖는다. :)
참조 : https://www.guru99.com/java-virtual-machine-jvm.html
Java Virtual Machine (JVM) & its Architecture
Java String has three types of Replace method replace replaceAll replaceFirst. With the help of...
www.guru99.com
https://www.geeksforgeeks.org/jvm-works-jvm-architecture/
How JVM Works - JVM Architecture? - GeeksforGeeks
JVM(Java Virtual Machine) acts as a run-time engine to run Java applications. JVM is the one that actually calls the main method present in a… Read More »
www.geeksforgeeks.org
'Programming Language > Java' 카테고리의 다른 글
| Java 를 이용한 Lazy Evaluation (0) | 2019.04.29 |
|---|---|
| JShell 을 이용한 Java Prototyping (0) | 2019.01.18 |
| Java 의 Thread Local 이란 (0) | 2018.11.28 |
| Java9 의 Feature 들에 대한 정리 (0) | 2018.11.07 |
| Java 클래스로더(ClassLoader)에 대한 이해 (0) | 2018.10.14 |




